
《流畅的 Python》读书笔记
两个问题
学了 Python 基础就够了吗?
前言的引言给出了答案:
要不这样吧,如果编程语言里有个地方你弄不明白,而正好又有个人用了这个功能,那就开枪把他打死。这比学习新特性要容易些,然后过不了多久,那些活下来的程序员就会开始用 0.9.6 版的 Python,而且他们只需要使用这个版本中易于理解的那一小部分就好了(眨眼) 。
—— Tim Peters
传奇的核心开发者, “Python 之禅”作者
这本书的目的是什么?
第十一章的杂谈里给出了答案:
这正是本书的主要目的:着重讲解这门语言的基本惯用法,让你的代码简洁、高效且可读,把你打造成熟练的 Python 程序员。
另外本书的前言里也有提及书本的目标读者和非目标读者。
如果你才刚刚开始学 Python,本书的内容可能会显得有些“超纲”。比难懂更糟的是,如果在学习 Python 的过程中过早接触本书的内容,你可能会误以为所有的 Python 代码都应该利用特殊方法和元编程(metaprogramming)技巧。我们知道,不成熟的抽象和过早的优化一样,都会坏事。
对内容的一些评价
从书目录结构来看,作者的眼界十分开阔,每章最后有小结、延伸阅读、和相关的一些杂谈。书的前一部分从 Python 特性出发,参考了很多语言的相关做法和实现,来解释 Python 的设计。
书中时常引用一些参考资料,有些是邮件列表里的讨论、维基百科、一些十分优秀的程序员的撰写的文章和演讲视频。这意味着你可以在某一个概念看到不同的观点,看到优秀的程序员是怎么思考一个问题的。
作者从1998年成为了 Python 程序员,是巴西一家培训机构的共同所有者,也为巴西的媒体、银行和政府部门教授 Python 课程,由此可见本书的代码会是十分透彻和浅显易懂的,事实也的确如此。从代码示例来看,作者为大部分代码提供了 doctest 测试,并且在为某一个知识点提供代码示例时,追求的是简单、直接,同时示例的难度是循序渐进的。加上作者在大部分代码行提供了说明,让读者能十分流畅地理解概念。(对比:《Go 程序设计语言》讲复数语法时用 Mandelbrot 图像作为示例,苦笑)
对翻译的一些评价
整体翻译还是不错的,几百页的书的勘误也才十多个,部分术语可能还要参考书里的术语翻译表,个人认为容易弄混的有特性(properties)和属性(attributes),还有函数(function)和方法(method)。后者的区别可以参考Difference between a method and a function,简单的说法就是函数(function)定义在类外面,而方法(method)定义在类里面,是类的一部分。两者也可以根据是否独立于对象来判断。
黄志斌:这本书第2次印刷时已经把“期物”改为“future”了。
P21 前面那种方式显然能够节省内存。 前者指的是 genexp,即生成器表达式。
章节简介
这本书的结构十分优秀,每一章节都有前言和小结,因此章节简介我偏向于写些零散的知识点和个人感受,会比较乱。大部分章节的章节简介最后会有个人阅读时做的笔记,章节简介没提及的内容可以看看我的笔记。
全部的笔记还可以在这里找到:Latias94/fluent-python-notes
第一章
第一章作者就介绍了 Python 中的特殊方法,特殊方法也是贯穿这本书的基础。
读这本书之前,自己通常会遇到__init__、__new__、__name__ == '__main__'等等的带双下划线的特殊方法,但是通过零散的知识点很难形成体系,而这本书涵盖了绝大部分的特殊方法,并且分章节详细地讨论其背后特殊方法的作用,而这一章就是了解特殊方法的第一步。
作者提到了合理的字符串表示形式:__repr__ 和 __str__。前者方便我们调试和记录日志,后者则是给终端用户看的。
作者开篇就提出了两个问题,第一个问题是:
为什么说 Python 最好的品质之一是一致性?
并且在第十二页给出了答案:
不能让特例特殊到开始破坏既定规则。
第二个问题是:
len(collection)和collection.len()有什么不同?和“Python 风格” (Pythonic)有什么关系?
核心开发者 Raymond Hettinger 的答案是:
实用胜于纯粹
practicality beats purity
——《The Zen of Python》
作者给出解释:
len 是特殊方法,是为了让 Python 自带的数据结构可以走后门,abs 也是同理。(解释:因为如果 x 是一个内置类型的实例,
len(x)的背后会用 CPython 直接从 C 结构体中读取对象的长度,不调用任何方法,以至于len(x)会非常快。)
…
这种处理方式在保持内置类型的效率和保证语言的一致性之间找到了一个平衡点,也印证了“Python 之禅”中的另外一句话:“不能让特例特殊到开始破坏既定规则。”
从这两个问题就能看出作者想要强调的是:「Python 风格 无处不在」。为了更好地理解 Python 实现,最好了解 Python 的设计风格。
笔记传送门:特殊方法
第二章
第二三四章主讲 Python 数据结构及其背后的实现,而第二章主要讲了可变类型与不可变类型的区别。
要想写出准确、高效和地道的 Python 代码,对标准库里的序列类型的掌握是不可或缺的。数据结构的产生就是为了满足各种不同的需求,例如能让用户在不复制内容的情况下操作同一个数组的不同切片的 memoryview,能高效处理矩阵、矢量等高级数值运算的 NumPy 和专为线性代数、数值积分和统计学而设计并基于 NumPy 的 SciPy。计算机科学家主要抽象了几大数据类型:字典、数组、列表等,这些数据类型都有不同的使用环境,使用好这些工具能让你事半功倍、节省不必要的消耗。
另外,在读这本书的前几天,我刚好在 Segmentfault 里面看到一个问题 python小白 问关于a+=a 和a=a+a的区别,当时看完答案还有点似懂非懂的感觉,而读完这章我能完全理解其区别所在了。
扩展阅读:problem-solving-with-algorithms-and-data-structure-using-python 中文版
笔记传送门:序列构成的数组
第三章
前一章提到了列表、元组这两种序列,以及它们的生成器表达式。这一章则介绍了散列表的基本概念、其背后的算法和由散列表实现的数据类型:字典和集合。
- 由于字典是由散列表实现的,因此字典的键必须是可散列的。
- set 类型本身不是可散列的(因为 set 是可变的),但其元素必须可散列。(这也是为什么 list 不能作为字典键的原因)
- frozenset 是可散列的。
- 散列表的实现导致它实现的数据类型效率很高,但这是以牺牲空间的代价所带来的。
“优化往往是可维护性的对立面”
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。举例而言,如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据 JSON 的风格,用由字典组成的列表来存放这些记录。用元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。
笔记传送门:字典和集合
第四章
目前没遇到过编码问题,不看。
第五章
第五章的主题是:高阶函数没这么重要了。
先来一段吐槽:
Lundh 提出的 lambda 表达式重构秘笈如果使用 lambda 表达式导致一段代码难以理解,Fredrik Lundh 建议像下面这样重构。
(1) 编写注释,说明 lambda 表达式的作用。
(2) 研究一会儿注释,并找出一个名称来概括注释。
(3) 把 lambda 表达式转换成 def 语句,使用那个名称来定义函数。
(4) 删除注释。
摘自“Functional Programming HOWTO”
现在函数式编程十分流行,但 Python 独特的语法使得 lambda、map、filter 和 reduce 这些函数没这么重要了,因为我们有 sum、all 等归约函数,还有 sorted、min、max 和 functools 这样的内置的高阶函数。
最后(5.10.2小节)讲了一个和函数柯里化(Currying)十分相像的概念——偏函数(Partial Application),这两者概念其实不一样。
笔记传送门:一等函数
第六章
作者从策略模式开始,讨论了一等函数在设计模式中的角色,并用一等函数简化了设计模式的实现方式,以此来展示 Pythonic 的设计模式应该是什么样子的。
扩展阅读:设计模式的python实现
笔记传送门:使用一等函数实现设计模式
第七章
第七章介绍了装饰器和闭包,作者给闭包下了一个清晰的定义:
闭包指延伸了作用域的函数,其中包含函数定义体中引用、但是不在定义体中定义的非全局变量。函数是不是匿名的没有关系,关键是它能访问定义体之外定义的非全局变量。
作者用一个闭包实例和作用相同的类来比较,引出了自由变量(free variable)的概念,以此指出闭包与普通函数不一样的地方——闭包会保留定义函数时存在的自由变量的绑定。在此之后,再引出可变类型与不可变类型对自由变量的影响,从而引出可能导致闭包失效的原因(第二章的主题:可变类型与不可变类型的区别),同时给出了解决办法:nonlocal 声明。
本章结尾的杂谈提到了「一般来说,实现“装饰器”模式时最好使用类表示装饰器和要包装的组件。」,也就是通过实现 __call__ 方法的类来实现装饰器。遗憾的是本书只通过函数来解说装饰器以助于理解,类装饰器没有提及多少。
笔记传送门:函数装饰器和闭包
第八章
不可变集合不变的是所含对象的标识。
第八章中,作者从「元组是不可变的,但是其中的值可以改变」引申到浅复制和深复制的区别。

浅复制带来的影响可以参考 example(点 foward 显示下一步)
作者还提到了两个容易忽略的函数参数引用问题:
- 不要使用可变类型作为参数的默认值
- 防御可变参数
最后一节讨论垃圾回收、del 命令,以及如何使用弱引用“记住”对象,而无需对象本身存在。
另外这章有意思的地方在于作者提到了一个常见的说法错误:「对引用式变量来说,说把变量分配给对象更合理,反过来说就有问题。毕竟对象在赋值之前就创建了。」
笔记传送门:对象引用、可变性和垃圾回收
第九章
要构建符合 Python 风格的对象,就要观察真正的 Python 对象的行为。
——古老的中国谚语
第九章主要讲如何编写 Pythonic 的对象。作者从构建一个 Vector 类型来介绍符合 Python 风格的类需要注意的地方,例如__repr__不要硬编码类名、类属性的私有化、格式规范微语言、散列化要注意的条件等。
作者还讲了构建一个可散列的类型所需要实现的条件:
- 正确的实现
__hash__和__eq__方法 - 不一定要实现只读属性,但是要保证实例的散列值绝不能变化。
类属性用于为实例属性提供默认值。Django 的类视图也大量用到了这个特性。
个人十分喜欢名称改写(属性的私有化)中的一张示意图:
「避免意外访问,但不能防止故意做错事。」,以此来提醒名称改写所实现的私有化自身的缺陷。
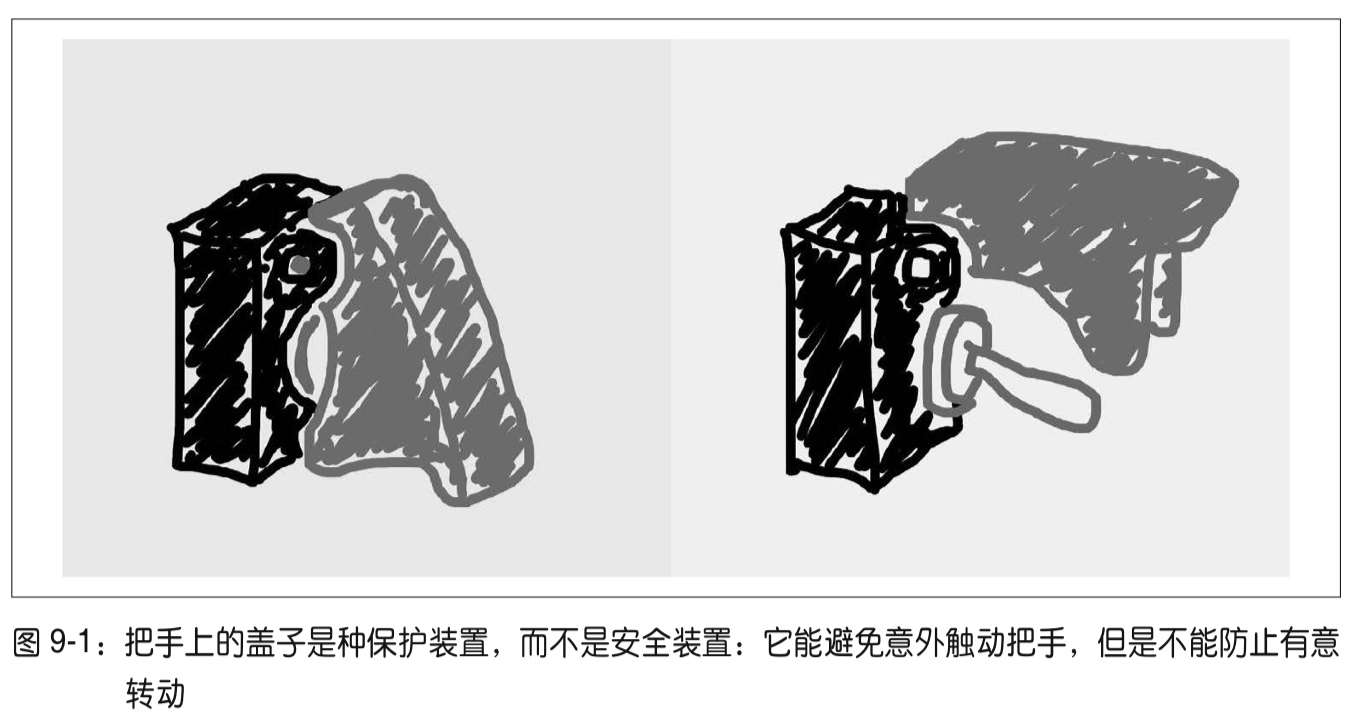
笔记传送门:符合 Python 风格的对象
第十章
不要检查它是不是鸭子、它的叫声像不像鸭子、它的走路姿势像不像鸭子,等等。具体检查什么取决于你想使用语言的哪些行为。 (comp.lang.python,2000 年 7 月 26 日)
——Alex Martelli
其中介绍了鸭子类型,指忽略对象的真正类型,转而关注对象有没有实现所需的方法、签名和语义。在 Python 中指免使用 isinstance 检查对象的类型。
如果我想实现一个序列,可以实现__init__、__len__、__getitem__等一序列的方法,使其行为像序列,那么这就是一个序列,这也就是人们所称的鸭子类型(duck typing)。
自己的理解:要明白自己希望的鸭子有哪些特性,只要我实现出来了,那么这就是鸭子。
Tips:
- 可以用
dir(slice)来查看序列的属性 - 当 Python 库文档查询不到方法的文档的时候,可以尝试用
help(slice.indices)来查询。( 直接查询__doc__属性的信息 )
第四小节讲可切片的序列需要关注的两个问题:
-
如果创建的序列内部由数组(或其他序列)实现,那么就要考虑切片对象的实现:切片返回的是自创建的序列对象 还是数组(或其他序列)?如果需要考虑,就是在
__getitem__方法里修改其实现方式。 -
动态存取属性,使序列能通过名称访问序列的属性(v.x,v.y代替v[0],v[1])。也提到了实现
__getitem__时可能会产生的问题,和解决方法。
章节末尾的杂谈提到了要遵循 KISS 原则(Keep it simple, stupid),不要过度设计协议。
笔记传送门:序列的修改、散列和切片
第十一章
本章讨论的话题是接口:从鸭子类型的代表特征动态协议,到使接口更明确、能验证实现是否符合规定的抽象基类(Abstract Base Class,ABC)
我们可能不需要写抽象基类,但是阅读本章能够教我们怎么阅读标准库和其他包中的抽象基类源码。
其中,作者引用了 Alex Martelli 的一篇文章,用表型系统学(phenetics)和支序系统学(cladistics)用水禽来类比抽象基类。(⊙﹏⊙)b
其中有第十章提到的「鸭子类型」,还有以前没提过的、描述一种新的 Python 编程风格的「白鹅类型」(goose typing)。
白鹅类型指,只要 cls 是抽象基类,即 cls 的元类是
abc.ABCMeta,就可以使用isinstance(obj, cls)。
对此,作者在章节小结里面提到:
借助「白鹅类型」,可以使用抽象基类明确声明接口,而且类可以子类化抽象基类或使用抽象基类注册(无需在继承关系中确立静态的强链接),宣称它实现了某个接口。
本章最后还介绍了和 Go 语言协议的功能十分类似的 __subclasshook__ 方法。
笔记传送门:接口:从协议到抽象基类
第十二章
分析 GUI 工具包 Tkhinter 的多重继承,并且展开分析了多次继承所带来的「菱形问题」,以及 Python 对应的解决方案——方法解析顺序(Method Resolution Order,MRO),最后作者给了八条关于处理多重继承的建议。
9.5.1. Multiple Inheritance 里面提到了继承顺序是深度优先从左至右不重复。
For most purposes, in the simplest cases, you can think of the search for attributes inherited from a parent class as depth-first, left-to-right, not searching twice in the same class where there is an overlap in the hierarchy.
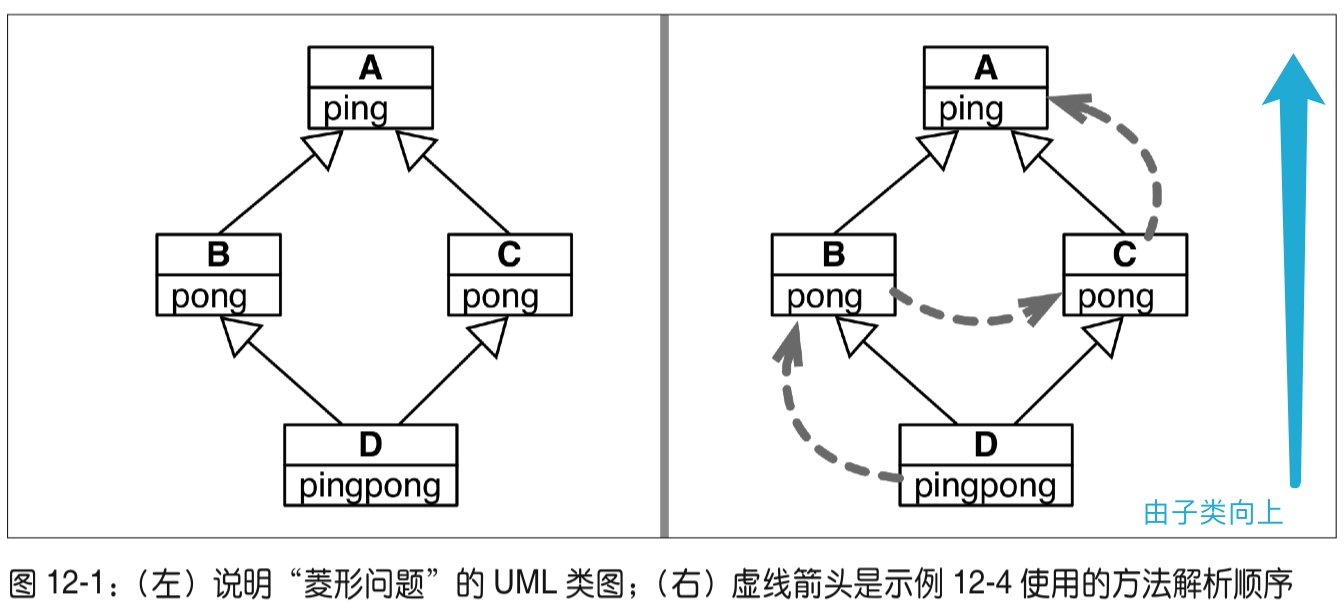
笔记传送门:继承的优缺点
第十三章
第十三章介绍了重载运算符的时候要考虑多重情况。
In the face of ambiguity, refuse the temptation to guess.
面对太多的可能,不要尝试猜测。(ZoomQuiet禅译)
——《The Zen of Python》
我们要严谨地对待可能会出现的操作数。
对于为什么需要重载运算符,在杂谈中作者提到了对于一部分人来说,重载运算符是十分重要的,符合人类直觉的表示法十分重要,例如金融工作会接触到一些由不同类型的参数(整数、或其他精度的数字)组成的公式。相比于不支持运算符重载的 Go 与 Java 语言,Python 采取了折中的方式,允许重载运算符,也有一些限制,如:不能重载内置类型的运算符、不能新建运算符、一些运算符也不能重载(is、and、or、not)。
笔记传送门:正确重载运算符
第十四章
作者分别介绍了迭代器、生成器表达式和生成器函数,并详细地列举了每个标准库生成器函数的用法。
前面介绍过 Python 内置的数据类型,如列表和元组,能让我们高效地访问数据集,但这些序列只能表示已知且长度有限的数据集。要表示无限长度的数据集,例如斐波拉契数列,就需要用到新的构造方式,这也是本章的话题的由来。
扫描内存中放不下的数据集时,我们要找到一种惰性获取数据项的方式,即按需一次获取一个数据项。这就是迭代器模式(Iterator pattern) 。
其中作者依然很注意用词,生成器是 “yields or produces” 生成值,而不是 “returns” 返回值,这样有助于理解生成器获取结果的过程,因为生成器不是以「常规」方式返回值的。
笔记传送门:可迭代的对象、迭代器和生成器
第十五章
介绍了 else 的三种用法与上下文管理器和 with 的作用,作者用__enter__、__exit__等方法手动地实现了一个上下文管理器,还介绍了 @contextmanager 作为另外一种更优雅的实现上下文管理器的方法。其中 @contextmanager 的 yield 语句也引出了第十六章中协程的概念。
笔记传送门:上下文管理器和else块
第十六章
建议看第十六、十七、十八章之前先理解五个概念:线程、进程、协程、并发和并行。
自己参考了:
在本章中,作者介绍了如何构建协程,和协程的一些使用场景,章节末尾,作者举了一个离散事件仿真示例,说明如何使用生成器代替线程和回调,实现并发。
在前些章节的基础上,作者在这章提到 yield 可以看做是控制流程的方式,即 yield 能获取值(.send(foo)),也能产出值(foo = yield),还能不获取和产出值(yield 后没有表达式)。因此,我们能用它来构建协程。
不管数据如何流动,yield 都是一种流程控制工具,使用它可以实现协作式多任务:协程可以把控制器让步给中心调度程序,从而激活其他的协程。
除了调用 .send(...) 方法发送数据,本章还介绍使用 yield from 结构驱动的生成器函数。
扩展阅读:
-
SICP in Python 有一段关于并行计算的非常精彩的解释:4.3 并行计算
-
SICP in Python 中协程的一节里着重讲了将复杂程序解构为小型、模块化组件的技巧:5.3 协程
笔记传送门:协程
第十七章
并发是计算机科学中最难的概念之一(通常最好别去招惹它) 。
——David Beazley Python 教练和科学狂人
在第十七章,作者用一个下载国旗图片的例子来介绍网络下载的三种风格:依序下载、concurrent.futures 模块(ThreadPoolExecutor 和 ProcessPoolExecutor 类)实现的并发下载和 asyncio 包实现的并发下载。作者还介绍了阻塞性 I/O 和 GIL,最后介绍了如何借助 concurrent.futures.ProcessPoolExecutor 类使用多进程。
future 指一种对象,表示异步执行的操作。
早期的计算机从单用户操作系统(同一时间只能运行一个任务)转变成多任务操作系统(同一时间可以运行多个任务),又由于多任务操作系统中程序经常抢夺系统资源而引发死锁这种缺陷,在 20 世纪 60 年代,计算机科学家就开始探索并发编程的道路,并发指交替执行多个任务,解决的就是前面提到的多任务操作系统的缺陷。直到现在,很多编程语言都为并发提供了支持,其中包括原生支持并发的 Go 语言,和有相关模块支持的 Python。
并发(concurrency)不是并行(parallelism)。并行是让不同的代码片段同时在不同的物理处理器上执行。并行的关键是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了。在很多情况下,并发的效果比并行好,因为操作系统和硬件的总资源一般很少,但能支持系统同时做很多事情。
——《Go 语言实战》
笔记传送门:使用future处理并发
第十八章
并发是指一次处理多件事。
并行是指一次做多件事。
二者不同,但是有联系。
一个关于结构,一个关于执行。
并发用于制定方案,用来解决可能(但未必)并行的问题。
——Rob Pike Go 语言的创造者之一
第十八章中,作者主要介绍了新的并发编程方式,对比了 asyncio.Task (协程)对象与 threading.Thread (线程)对象的区别,包括 Python 包使用方式的区别和中断时协程与线程的区别:锁的保留。章节尾,作者介绍了 asyncio 包的使用和并发编程需要注意的地方。
笔记待补
第十九章
第十九章主要介绍了动态属性编程。
1 | class Foo(object): |
这就叫做动态属性(dynamic attribute),不同于属于静态语言的 Java 需要依靠 setter 和 getter 方法,Python 能十分方便地设置属性和读取属性。
作者拿 FrozenJSON 类做例子:把嵌套的字典和列表转换成嵌套的 FrozenJSON 实例和实例列表。FrozenJSON 类的代码展示了如何使用特殊的 __getattr__ 方法(处理属性的函数)在读取属性时即时转换数据结构。
作者还介绍了很多处理属性的属性和函数以及利用特性(@properties)来修改设置属性和读取属性的方式。
笔记传送门:动态属性和特性
第二十章
有时候看书看着就忘了一些名词是什么了,因此参考了下【译】Python描述符指南,描述符类就是实现描述符协议的类。
相比于第十九章中利用特性(@properties)来修改属性的存取逻辑,第二十章主要介绍了描述符——对多个属性运用相同存取逻辑的一种方式。两者的区别是特性有时更合适和简单,而描述符更灵活。这章还介绍了覆盖型与非覆盖型描述符的对比,最后也给出了使用描述符的建议和优缺点。
笔记传送门:属性描述符
第二十一章
(元类)是深奥的知识,99% 的用户都无需关注。如果你想知道是否需要使用元类,我告诉你,不需要(真正需要使用元类的人确信他们需要,无需解释原因) 。
——Tim Peters
Timsort 算法的发明者,活跃的 Python 贡献者
上面是第二十一章的引言,我听从这位传奇开发者的建议,没有看。
总结
整本书都在强调如何最大限度地利用 Python 标准库以及讲述 Python 背后的设计思想。身处众多动态编程语言中间,Python 无疑是独行独立的,这也是为什么很多 Python 开发者骄傲地宣称自己是一名 Pythonista。
自己只是不求甚解地通读了一遍书,学到了很多,但书中仍有太多不熟悉的知识点。因为假期不多了,只能等日后二刷这本书。过一遍这本书最大的收获莫过于在面对问题的时候,自己的工具箱又多了不少工具,即使这工具还不太「趁手」。其中感受最深的就是现在看一些 Segmentfault 或 StackOverflow 问题的答案的时候不再那么毫无头绪,并开始试着从前辈们的角度思考问题。另外书中多次提到 Django 的一些实现方式,对自己日后读源码的时候有帮助。
仓促本身就是最要不得的态度。当你做某件事的时候,一旦想要求快,就表示你再也不关心它,而想去做别的事。
——罗伯特 · M · 波西格 《禅与摩托车维修艺术》
自己的确因为阅读计划的期限而读的仓促了一些,这句话放到文尾,提醒自己在读下一本书的时候,尽量做到静下心来。
 wechat
wechat alipay
alipay





