
Compute Shader 简介
做游戏的时候,我们经常要面对各种优化问题。DOTS 技术栈的出现提供了一种 CPU 端的多线程方案,那么我们是否也能将一些计算转到 GPU 上面,从而平衡好对 CPU 和 GPU 的使用呢?对我而言,以前使用 GPU 无非是通过写 vert/frag shader、做好渲染相关的设置等操作,但实际上我们还能使用 GPU 的计算能力来帮我们解决问题。Compute Shader 就是我们跟 GPU 请求计算的一种手段。
本文将从并行架构开始,依次讲解一个最简单的 Compute Shader的编写、线程与线程组的概念、GPU 结构和其计算流水线,并讲解一个鸟群 Flocking 的实例,最后介绍 Compute Shader 的应用。全文较长,读者可以通过目录挑想看的看。
Compute Shader 也和传统着色器的写法十分不一样,写传统 Shader 写怕了的同学请放心~
介绍
当今的 GPU 已经针对单址或连续地址的大量内存处理(亦称为流式操作,streaming operation)进行了优化,这与 CPU 面向内存随机访问的设计理念则刚好背道而驰。再者,考虑到要对顶点与像素分别进行单独的处理,因此 GPU 现已经采用了大规模并行处理架构。例如,NVIDIA 公司开发的 “Fermi” 架构最多可支持 16 个流式多处理器(streaming multiprocessor, SM),而每个流式处理器又均含有 32 个 CUDA 核心,也就是共 512 个 CUDA 核心。
CUDA 与 OpenCL 其实就是通过访问 GPU 来编写通用计算程序的两组不同的 API。

现代的 CPU 有 4-8 个 Core,每个 Core 可以同时执行 4-8 个浮点操作,因此我们假设 CPU 有 64 个浮点执行单元,然而 GPU 却可以有上千个这样的执行单元。仅仅只是比较 GPU 和 CPU 的 Core 数量是不公平的,因为它们的职能不同,组织形式也不同。
显然,图形的绘制优势完全得益于 GPU 架构,因为这架构就是专为绘图而精心设计的。但是,一些非图形应用程序同样可以从 GPU 并行架构所提供的强大计算能力中受益。我们将 GPU 用于非图形应用程序的情况称为通用 GPU 程序设计(通用 GPU 编程。General Purpose GPU programming, GPGPU programming)。当然,并不是所有的算法都适合由 GPU 来执行,只有数据并行算法(data-parallel algorithm) 才能发挥出 GPU 并行架构的优势。也就是说,仅当拥有大量待执行相同操作的数据时,才最适宜采用并行处理。[1]
粒子系统是一个例子,我们可简化粒子之间的关系模型,使它们彼此毫无关联,不会相互影响,以此使每个粒子的物理特征都可以分别独立地计算出来。
对于 GPGPU 编程而言,用户通常需要将计算结果返回 CPU 供其访问。这就需将数据由显存复制到系统内存,虽说这个过程的速度较慢(见下图),但是 GPU 在运算时所缩短的时间相比却是微不足道的。 针对图形处理任务来说,我们一般将运算结果作为渲染流水线的输入,所以无须再由 GPU 向 CPU 传输数据。例如,我们可以用计算着色器(Compute Shader)对纹理进行模糊处理(blur),再将着色器资源视图(shader resource view,DirectX 的概念),与模糊处理后的纹理相绑定,以作为着色器的输入。
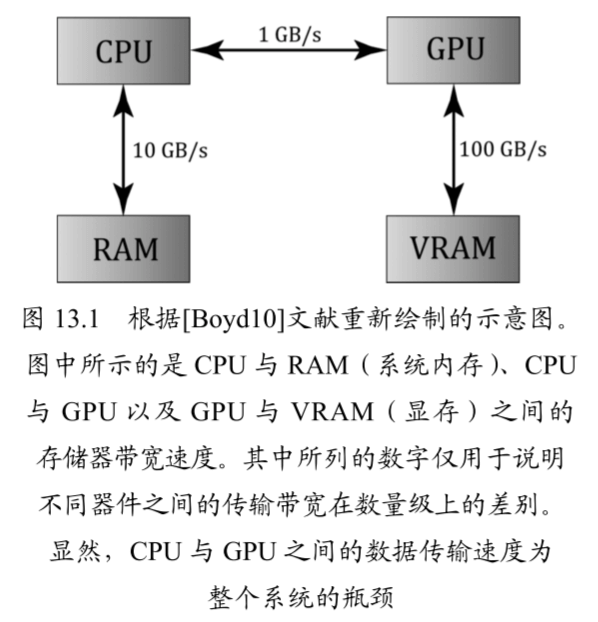
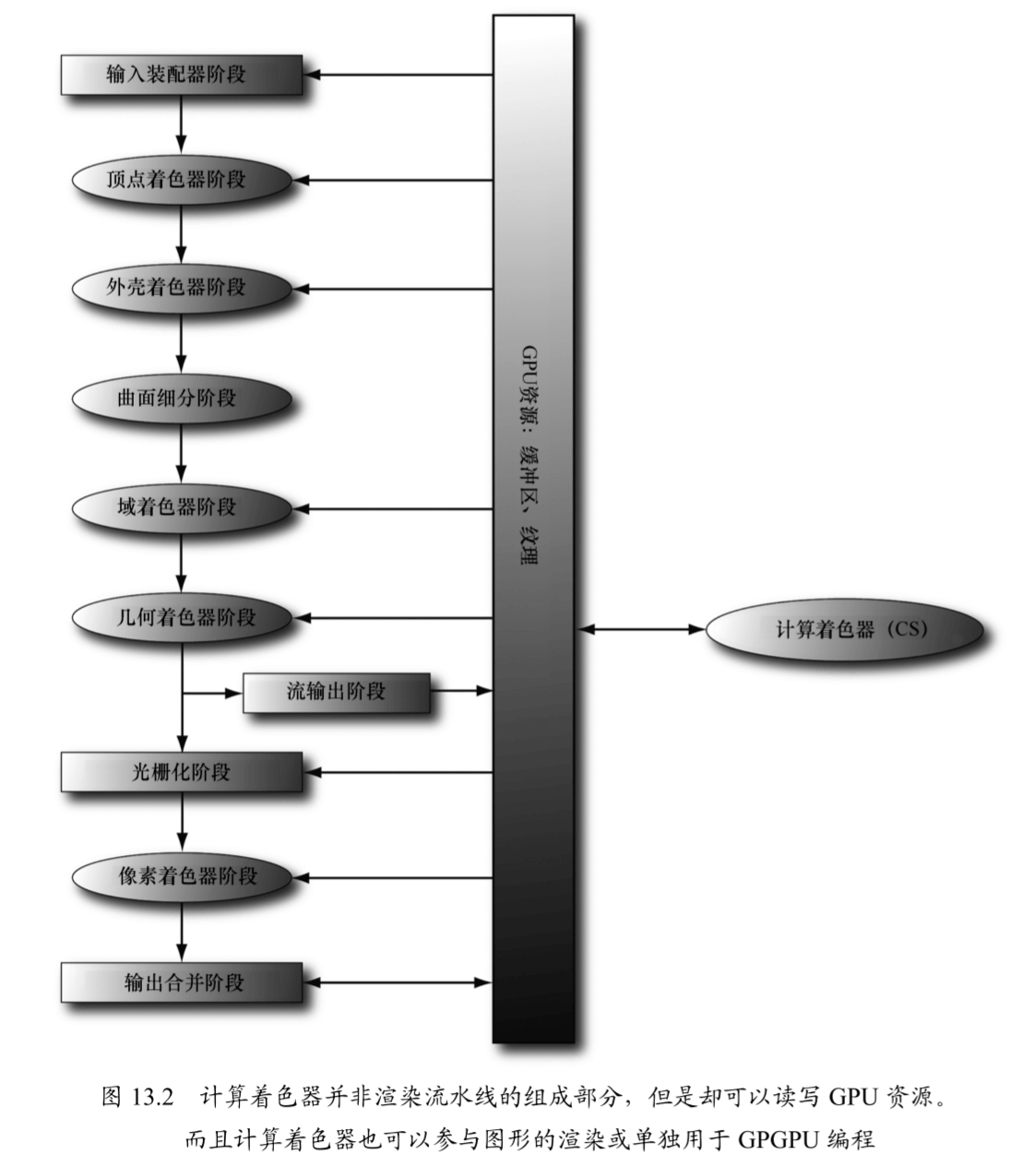
计算着色器虽然是一种可编程的着色器,但 Direct3D 并没有将它直接归为渲染流水线中的一部分。虽然如此,但位于流水线之外的计算着色器却可以读写 GPU 资源。从本质上来说,计算着色器能够使我们访问 GPU 来实现数据并行算法,而不必渲染出任何图形。正如前文所说,这一点即为 GPGPU 编程中极为实用的功能。另外,计算着色器还能实现许多图形特效——因此对于图形程序员来说,它也是极具使用价值的。前面提到,由于计算着色器是 Direct3D 的组成部分,也可以读写 Direct3D 资源,由此我们就可以将其输出的数据直接绑定到渲染流水线上。
最简单的 Compute Shader
现在我们来看看一个最简单的 Compute Shader 的结构。
Unity 右键 → Create → Shader → Compute Shader 就可以创建一个最简单的 Compute Shader。
Compute Shader 文件扩展名为 .compute,它们是以 DirectX 11 样式 HLSL 语言编写的。
1 |
|
第 1 行:一个计算着色器资源文件必须包含至少一个可以调用的 compute kernel,实际上这个 kernel 对应的就是一个函数,该函数由 #pragma 指示,名字要和函数名一致。一个 Shader 中可以有多个内核,只需定义多个 #pragma kernel functionName 和对应的函数即可,C# 脚本可以通过 kernel 的名字来找到对应要执行的函数( shader.FindKernel(functionName))。
第 3 行: RWTexture2D 是一种可供 Compute Shader 读写的纹理,C# 脚本可以通过 SetTexture() 设置一个可读写的 RenderTexture 供 Compute Shader 修改像素颜色。其中 RW 代表可读写。
第 5 行:numthreads 设置线程组中的线程数。组中的线程可以被设置为 1D、2D 或 3D 的网格布局。线程组和线程的概念下文会提到。
第 6 行:CSMain 为函数名,需要和 pragma 定义的 kernel 名一一对应。一个函数体代表一个线程要执行的语句,传进来的 SV_DispatchThreadID 是三维的线程 id,下文会提到。
第 9 行:根据当前线程 id 索引到可读写纹理对应的像素,并设置颜色。
C# 脚本这边
1 | private void InitShader() |
第 4 行:一个 Compute Shader 可能有多个 Kernel,这里根据名字找到需要的 KernelIndex,这样脚本才知道要把数据送给哪一个函数运算。
第 6、7 行:创建一个支持随机读写的 RenderTexture 。
第 10 行:为 Compute Shader 设置要读写的纹理。
第 11 行:设置好要执行的线程组的数量,并开始执行 Compute Shader。线程组数量的设置下文会提到。
将 Compute Shader 在 Inspector 赋值给脚本,然后将脚本挂在一个有 Image 组件的 GameObject 下,就能看到蓝色的图片。

到现在我们应该大概明白了:
- kernel 函数里面执行的是一个线程的要执行的逻辑。
- 我们需要设置线程组的数量(Dispatch)、和线程组内线程的数量(numthreads)。
- 我们可以为 Compute Shader 设置纹理等可读写资源。
那么什么是线程组和线程呢?我们又该如何设置数量?
如何划分工作:线程与线程组
在 GPU 编程的过程中,根据程序具体的执行需求,可将 线程 划分为由 线程组(thread group) 构成 的网格(grid)。
numthread 和 Dispatch 的三维 Grid 的设置方式只是方便逻辑上的划分,硬件执行的时候还会把所有线程当成一维的。因此 numthread(8, 8, 1) 和 numthread(64, 1, 1) 只是对我们来说索引线程的方式不一样而已,除外没区别。
线程组构成的 3D 网格
下图是 Dispatch(5,3,2), numthreads(10,8,3) 时的情况。
注意下图 Y 轴是 DirectX 的方向,向下递增,而 Compute Shader 中 Y 轴是相反的,向上递增,这里参考网格内的结构和线程组与线程的关系即可。
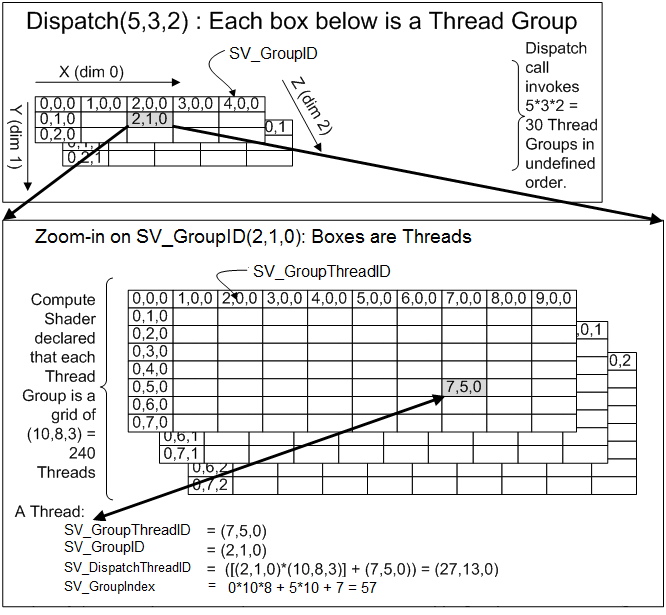
上图中还显示了 SV_DispatchThreadID 是如何计算的。
不难看出,我们能够根据需求定义出不同的线程组布局。例如,可以定义一个具有 X 个线程的单行线程组 [numthreads(X, 1, 1)] 或内含 Y 个线程的单列线程组 [numthreads(1, Y, 1)]。
还可以通过将维度 z 设为 1 来定义规模为 的 2D 线程组,形如 [numthreads(X, Y, 1)]。我们应结合所遇到的具体问题来选择适当的线程组布局。
例如当我们处理 2D 图像时,需要让每一个线程单独处理一个像素,就可以定义 2D 的线程组。假设我们 numthreads 设置为 (8, 8, 1),那么一个线程组就有 个线程,能处理 的像素块(内含 64 个像素点)。
那么如果我们要处理一个 分辨率的纹理,那么需要多少个线程组呢?
x 和 y 方向都需要 个线程组。
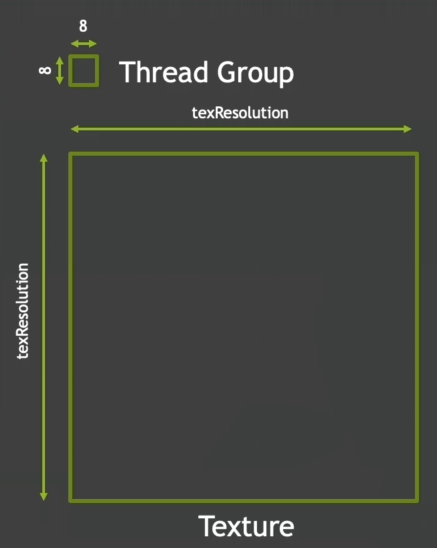
可以通过线程组来划分要处理哪些像素块()
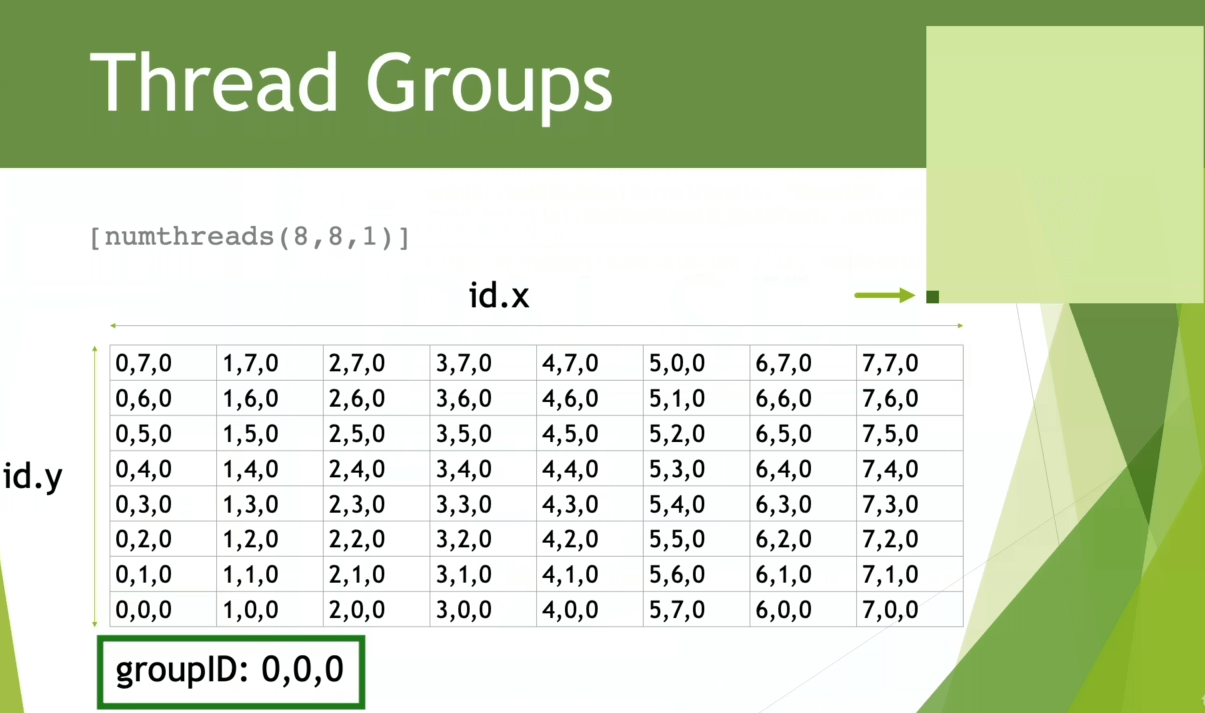
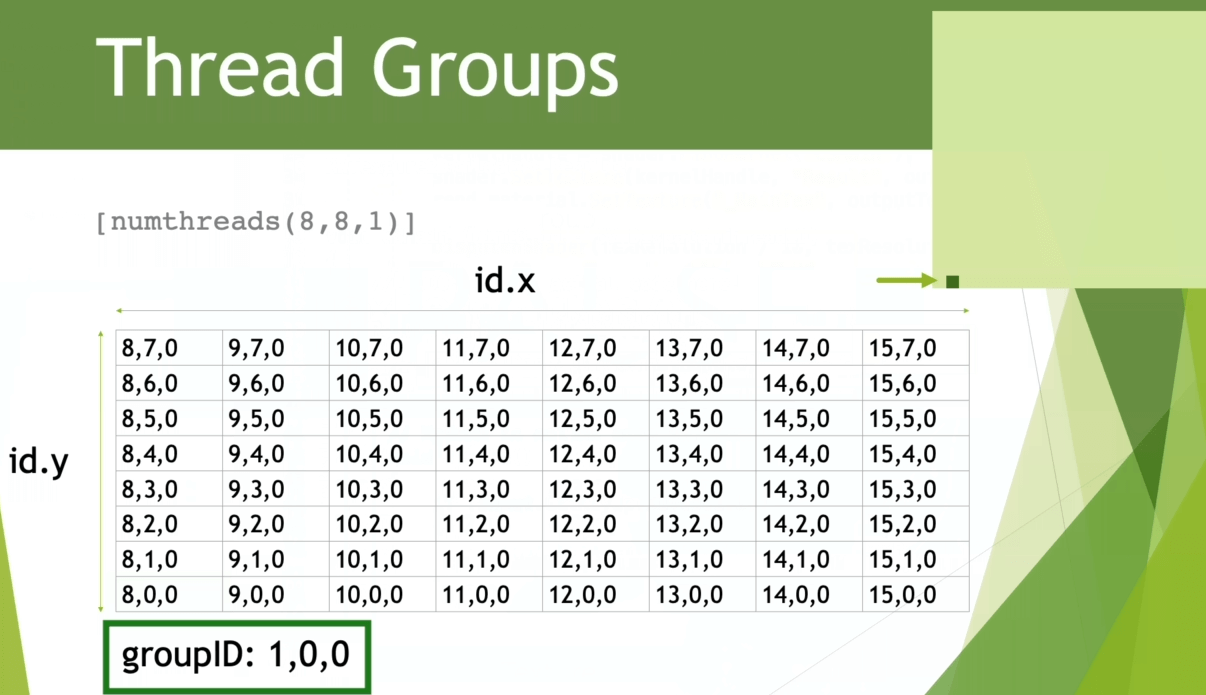
numthreads 有最大线程限制,具体查阅不同平台的文档:numthreads 。
前面介绍了如何设置线程组和线程的数量,现在介绍线程组和线程在硬件的运行形式。
线程组的 GPU 之旅
我们知道 GPU 会有上千个“核心”,用 NVIDIA 的说法就是 CUDA Core。
- SP:最基本的处理单元,streaming processor,也称为 CUDA core。最后具体的指令和任务都是在 SP 上处理的。GPU 进行并行计算,也就是很多个 SP 同时做处理。我们所说的几百核心的 GPU 值指的都是 SP 的数量;
- SM:多个 SP 加上其他的一些资源组成一个 streaming multiprocessor。也叫 GPU 大核,其他资源如:warp scheduler,register,shared memory 等。SM 可以看做 GPU 的心脏(对比 CPU 核心),register 和 shared memory 是 SM 的稀缺资源。CUDA 将这些资源分配给所有驻留在 SM 中的 threads。因此,这些有限的资源就使每个 SM 中 active warps 有非常严格的限制,也就限制了并行能力。
这些核心被组织在流式多处理器(streaming multiprocessor, SM)中,一个线程组运行于一个多处理器(SM)之上。每一个核心同一时间可以运行一个线程。
流式多处理器(streaming multiprocessor, SM)是 Nvidia 的说法,AMD 对应的单元则是 Compute Unit。
因此,对于拥有 16 个 SM 的 GPU 来说,我们至少应将任务分解为 16 个线程组,来让每个多处理器都充分地运转起来。但是,要获得更佳的性能,我们还应当令每个多处理器至少拥有两个线程组,使它能够切换到不同的线程组进行处理,以连续不停地工作(线程组在运行的过程中可能会发生停顿,例如,着色器在继续执行下一个指令之前会等待纹理的处理结果,此时即可切换至另一个线程组)。
SM 会将它从 Gigathread 引擎(NVIDIA 技术,专门管理整个流水线)那收到的大线程块,拆分成许多更小的堆,每个堆包含 32 个线程,这样的堆也被称为:warp (AMD 则称为 wavefront)。多处理器会以 SIMD32 的方式(即 32 个线程同时执行相同的指令序列)来处理 warp,每个 CUDA 核心都可处理一个线程。
“Fermi” 架构中的每个多处理器都具有 32 个 CUDA 核心。
每一个线程组都会被划分到一个 Compute Unit 来计算,线程组中的线程由 Compute Unit 中的 SIMD 部分来执行。
如果我们定义 numthreads(8, 2, 4),那么每个线程组就有 个线程,这一整个线程组会被分成两个 warp,调度到单个 SIMD 单元计算。

单个 SM 处理逐个 warp,当一个 warp 暂时需要等待数据的时候,就可以先换其他 warp 继续执行。
如何设置好线程组的大小
我们应当总是将线程组的大小设置为 warp 尺寸的整数倍。让 SM 同时容纳多个 warp,能够以防一些情况。例如有时候为了等待某些数据就绪,你不得不停下来。比如说,我们需要通过法线纹理贴图来计算法线光照,即使该法线纹理已经在 Cache 中了,访问该资源仍然会有所耗时,而如果它不在 Cache 中,那就更加耗时了。用专业术语讲就是 Memory Stall(内存延迟)。与其什么事情也不做,不如将当前的 Warp 换成其它已经准备就绪的 Warp 继续执行。[2]

上图来自:DirectCompute Lecture Series 210: GPU Optimizations and Performance
NVIDIA 在 Maxwell 更改了 SM 的组织方式,即 SMM——全新的 SM 架构。每个 SM 分为四个独立的处理块,每个处理块具备自己的指令缓冲区、调度器以及 32 个 CUDA 核心。因此 Maxwell 中可以同时运行 4 个以上的 Warp,实际上,在 GTC2013 大会上的一个 CUDA 优化视频里讲到,在常用 case 中推荐使用 30 个以上的有效 Warp,这样才能确保 Pipeline 的满载利用率。
—— Guohui Wang
NVIDIA 公司生产的图形硬件所用的 warp 单位共有 32 个线程。而 ATI 公司采用的 “wavefront” 单位则具有 64 个线程,且建议为其分配的线程组大小应总为 wavefront 尺寸的整数倍。另外,值得一提的是,不管是 warp 还是 wavefront,它们的大小在未来几代中都有可能发生改变。
总之,每个 SM 的操作度是 warp,但是每个 SM 可以同时处理多个 warp。然后因为有内存等待(memory stall)的问题,同一个 thread block 有可能需要等待内存才做,因此可以使用多个线程组交叉运行。warp 对我们是不可见和不可编程的,我们可编程的只有线程组。[3]
还可以参考 GPU Open 中 Compute Shader 部分。
GPU Compute Unit
接下来我们看一下 GPU 内部的结构,这里的内容来自 Compute Shaders: Optimize your engine using compute / Lou Kramer, AMD,Lou Kramer 以 AMD 的 GCN 架构为例,介绍了 GPU 大体的结构。
这里 GCN 就是一个 Compute Unit,Vega 64 显卡有 64 个 Compute Unit。
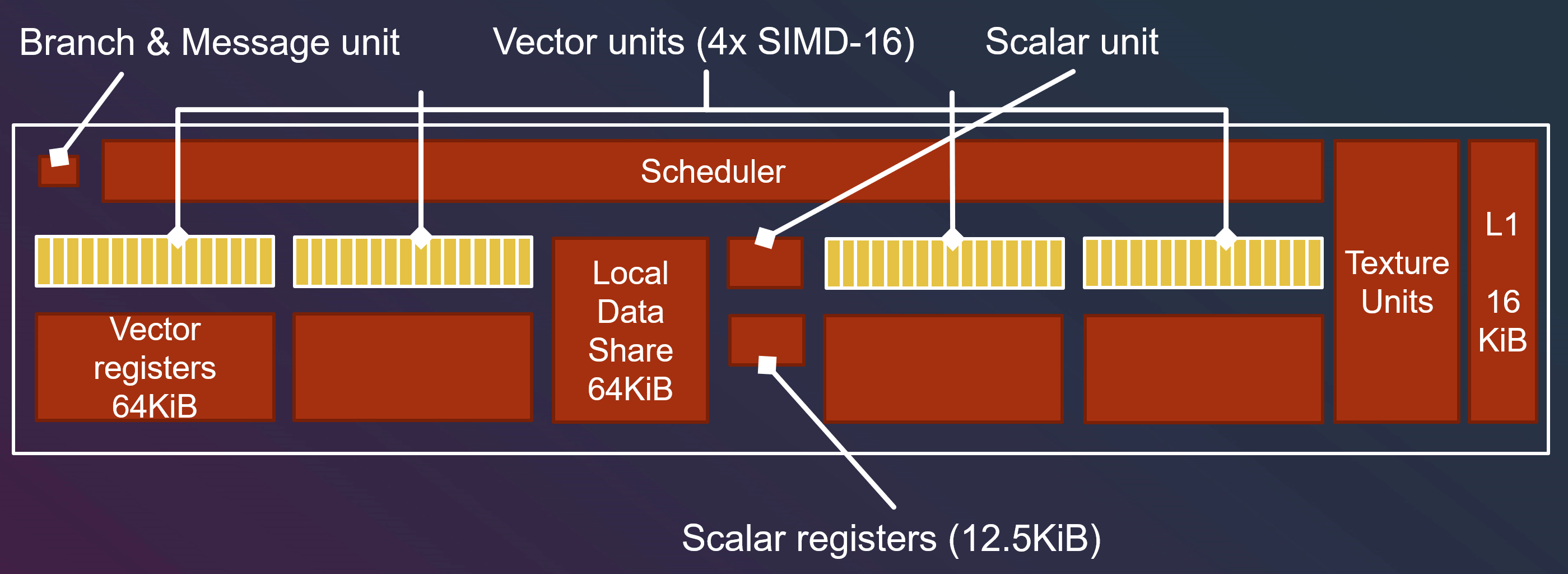
GCN 有 4 个 SIMD-16 单元(即 16 个线程同时执行相同的指令序列)。
线程间交流
多个线程组间的交流
上面提到,线程并不能访问其他组中的共享内存。如果线程组需要互相交流,那么就需要 L2 cache 来支持。但是 L2 cache 性能肯定会有折扣,因此我们要保证组间的交流尽可能少。
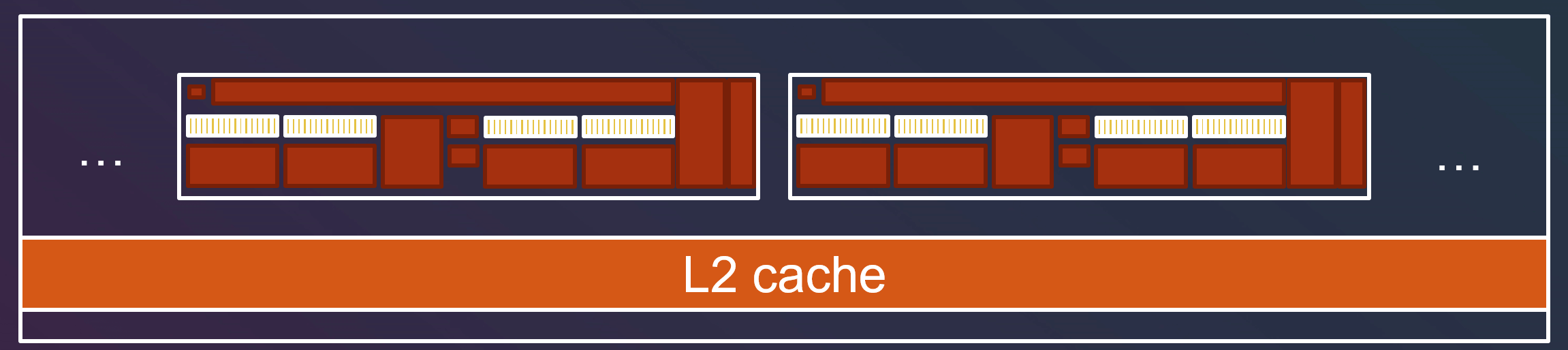
单个线程组内的交流
如果单个线程组内线程需要互相交流,则需要 Local Data Share (LDS) 来完成。
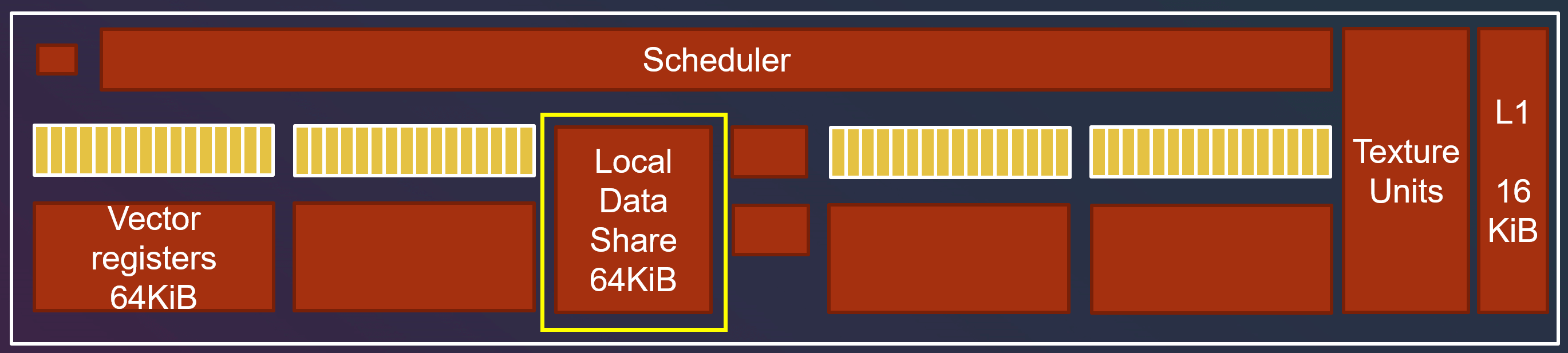
LDS 会被其他着色阶段(shader stage)使用,例如像素着色器就需要 LDS 来插值。但是 Compute Shader 的用途和传统着色器不一样,不是必须要 LDS,因此我们可以随意地使用 LDS。
1 | groupshared float data[8][8]; |
需要组内共享的变量前加 groupshared ,同时为了保证其他线程也能读到数据,我们也需要通过 Barrier 来保证他们读的时候 LDS 里面有需要的数据。
LDS 比 L1 cache 还快!
Vector Register 和 Scalar Register
如果有些变量是线程独立的,我们称之为 “non-uniform” 变量。(如果一个线程组内有 64 个线程,就要存 64 份数据)
如果有些变量是线程间共享的,我们称之为 “uniform” 变量,例如线程组 id 是组内每个线程都一样的。(每个线程组内只存 1 份数据)
“non-uniform” 变量会被储存到 Vector Register(VGPR, vector general purpose register)中。
“uniform” 变量会被储存到 Scalar Register(SGPR, scalar general purpose register)中。
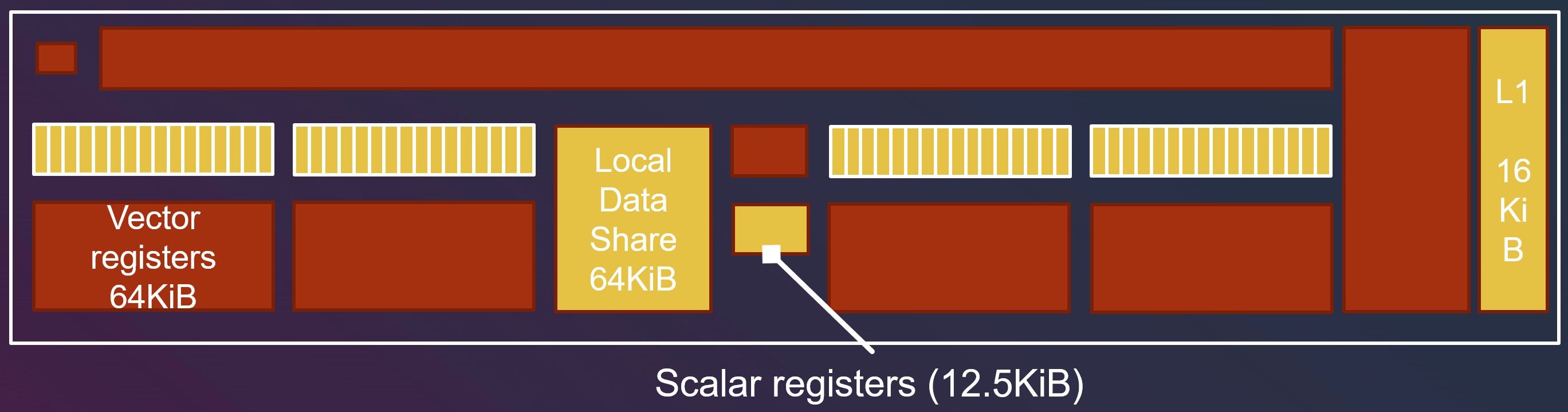
如果用了过多 “non-uniform” 变量导致 Vector Register 装不下,就会导致分配给 SIMD 的线程组数量降低。
与传统着色器执行流程的异同
Vert-Frag Shader
-
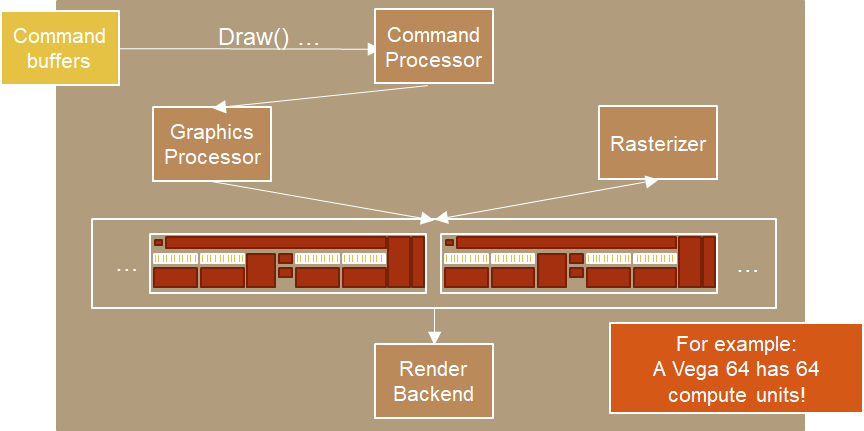
首先 Command Processor 会收集并处理所有命令,发送到 GPU,并告知下一步要做什么。
-
Draw()命令发送后,Command Processor 告知 Graphics Processor 要做的事情。我们可以将 Graphics Processor 看作是输入装配器(Input Assembler)的硬件对应的部分。
-
然后类似于顶点着色器这些就会被送到 Compute Unit 去计算,处理完会到 Rasterizer (光栅器),并返回处理好的像素到 Compute Unit 执行像素着色(Pixel shader)。
-
最后才会输出到 RenderTarget 。
下图中,AMD 显卡架构中的 Compute Unit 相当于 nVIDIA GPUs 中的流式多处理器(streaming multiprocessor, SM)。
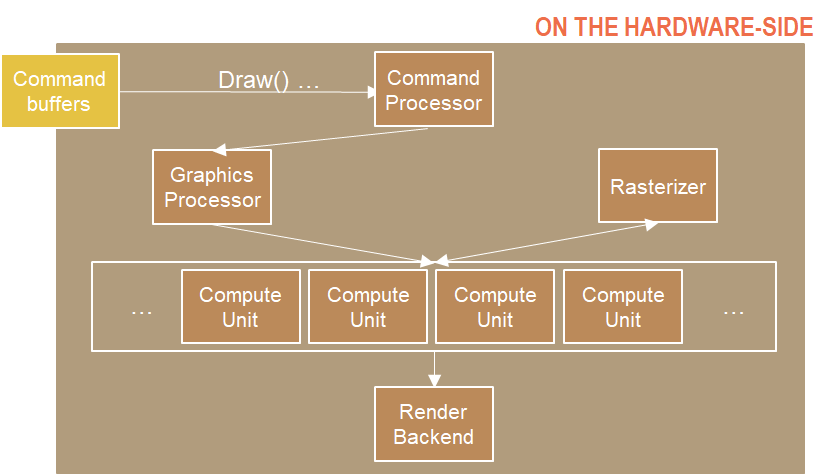
Compute Shader
- 首先 Command Processor 仍会收集并处理所有命令,发送到 GPU。
- 我们不需要传数据到 Graphics Processor,因为这不是一个 Graphics Command,而是直接传到 Compute Unit。
- Compute Unit 开始处理 Compute Shader,输入可以有 constants 和 resources(对应 DirectX 的 Resource 可以绑定到渲染管线的资源,例如顶点数组等),输出可以有 writable resources(UAV, Unordered Access View 能被着色器写入的资源视图)。
总结
因此,如果我们用了 Compute Shader,可以不通过渲染管线,跳过 Render Output,使用更少硬件资源,利用 GPU 来完成一些渲染不相关的工作。
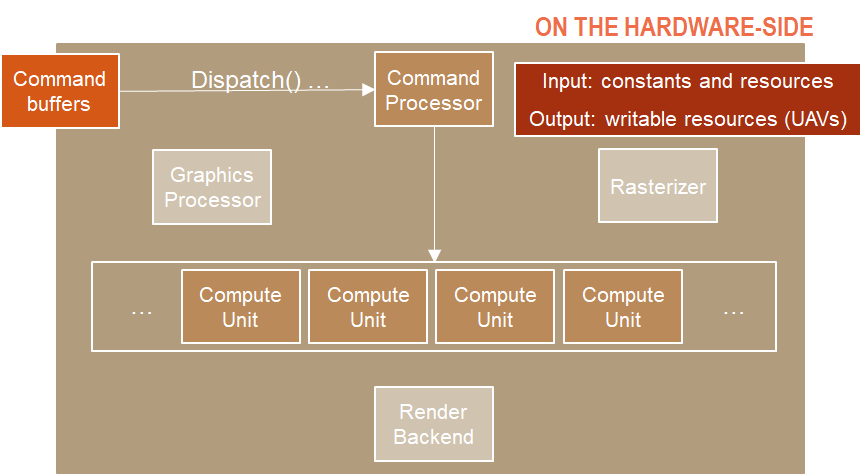
此外,Compute Shader 的流水线需要的信息也更少。

Boids 示例
讲完了理论,这里来看看我们在 Unity 中使用 Compute Shader 来做一个鸟群(Boids)的 demo。
群落算法可以参考:Boids (Flocks, Herds, and Schools: a Distributed Behavioral Model)
代码示例地址:Latias94/FlockingComputeShaderCompare
群落算法简单来讲,就是模拟生物群落的自组织特性的移动。
Craig Reynolds 在 1986 年对诸如鱼群和鸟群的运动进行了建模,提出了三点特征来描述群落中个体的位置和速度:
- 排斥(separation):每个个体会避免离得太近。离得太近需要施加反方向的力使其分开。
- 对齐(Alignment):每个个体的方向会倾向于附近群落的平均方向。
- 凝聚(Cohesion):每个个体会倾向于移动到附近群落的平均位置。
在这个示例中,我们可以将每一只鸟的位置和方向用一个线程来计算,Compute Shader 负责遍历这只鸟的周围鸟的信息,计算出这只鸟的平均方向和位置。C# 脚本则负责每一帧传入凝聚(Cohesion)的位置、经过的时间,再从 Compute Shader 获取每一只鸟的位置和朝向,设置到每一只鸟的 Transform 上。
设置数据
文章开头的例子中,脚本给 Shader 设置了 RWTexture2D<float4> ,让 Compute Shader 能直接在 Render Tecture 设置颜色。
对于其他类型的数据,我们首先要定义一个结构(Struct),再通过 ComputeBuffer 与 Compute Shader 交流数据。
1 | // FlockingGPU.cs |
获取数据
在开头最简单的 Compute Shader 一节中,我介绍了需要 Dispatch 去执行 Compute Shader 的 Kernel。
下面的 Update,设置了每一帧会变的参数,Dispatch 之后,再通过 GetData 阻塞等待 Compute Shader kernel 的计算结果,最后对每一个 Boid 结构赋值。
1 | // FlockingGPU.cs |
在 Compute Shader 中,也要定义一个 Boid 结构和相对应的 RWStructuredBuffer<Boid> 来用脚本传来的 Compute Buffer。Shader 主要就是对一只鸟遍历一定范围内的鸟群的信息,计算出结果返回给脚本。
1 | // SimpleFlocking.compute |
Dispatch 之后 GetData 是阻塞的,如果想异步地获取数据,Unity 2019 新引入一个 API:AsyncGPUReadbackRequest ,可以让我们先发送一个获取数据的请求,再每一帧去查询数据是否计算完。也有同学用了测出第一次调用耗时较多等问题,具体可以参考:Compute Shader 功能测试(二)。
下面是 100 只鸟的结果:

通过 Compute Shader,我们可以通过 Compute Shader 在 GPU 直接计算好需要计算的东西(例如位置、mesh 顶点等),并与传统着色器共享一个 ComputeBuffer ,直接在 GPU 渲染,这样就省去渲染时 CPU 再次传数据给 GPU 的耗时。我们也可以将 Compute Shader 计算后的数据返回给 CPU 再做额外的计算。总而言之,Compute Shader 十分灵活。
CPU 端计算 vs GPU 端计算
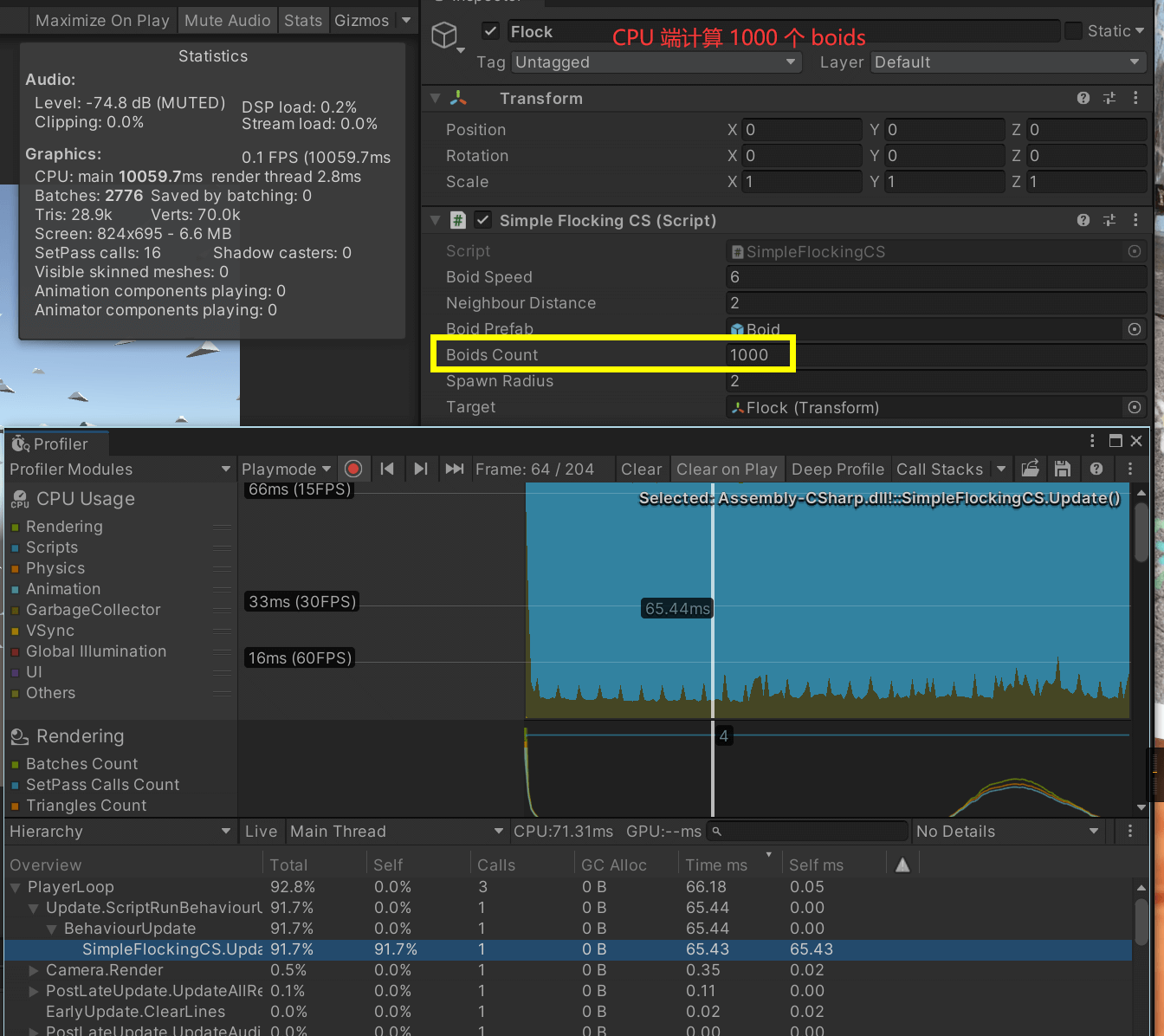
假设我们在 CPU 端不用任何 DOTS,直接在每个 Update 中 for 每个鸟计算朝向和位置,这样性能是非常差的。
下图是把计算都放到 C# Update 中的 Profile:
如果放到 Compute Shader 计算,每个 Update 更新数据,这样 CPU 消耗小了很多。
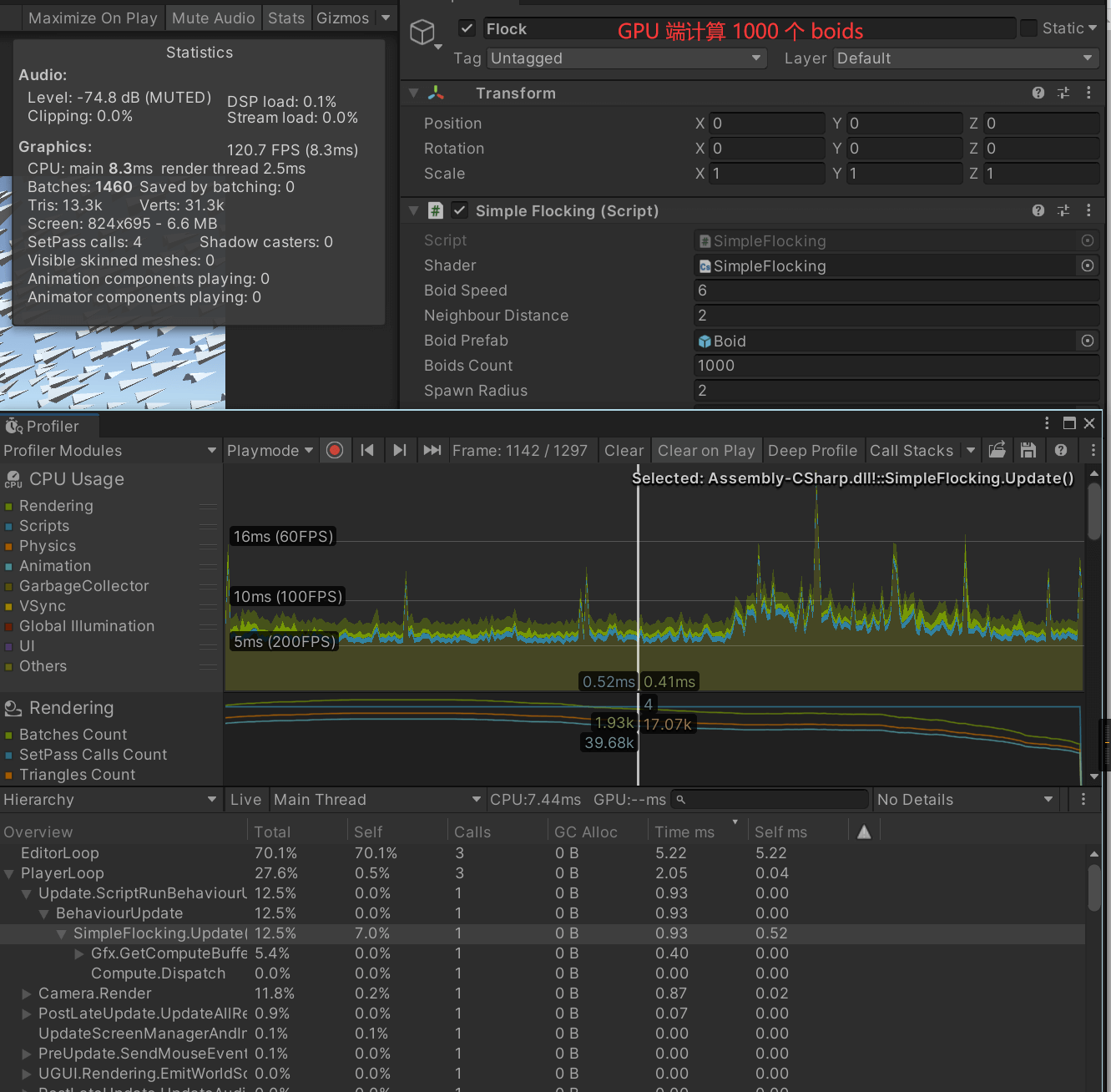
感兴趣的朋友可以对比下 FlockingCPU.cs 和 FlockingGPU.cs 的代码,会发现两者的代码其实十分相似,只不过前者把 for loop 放到脚本,后者放到了 Compute Shader 中而已,因此如果大家觉得有一些地方十分适合并行计算,就可以考虑把这部分计算放到 GPU 计算。
Profile Compute Shader
我们可以通过 Profiler 来看 GPU 利用情况,通常这个面板是隐藏的,需要手动打开。
也可以通过 RenderDoc 来看,这里不展示。
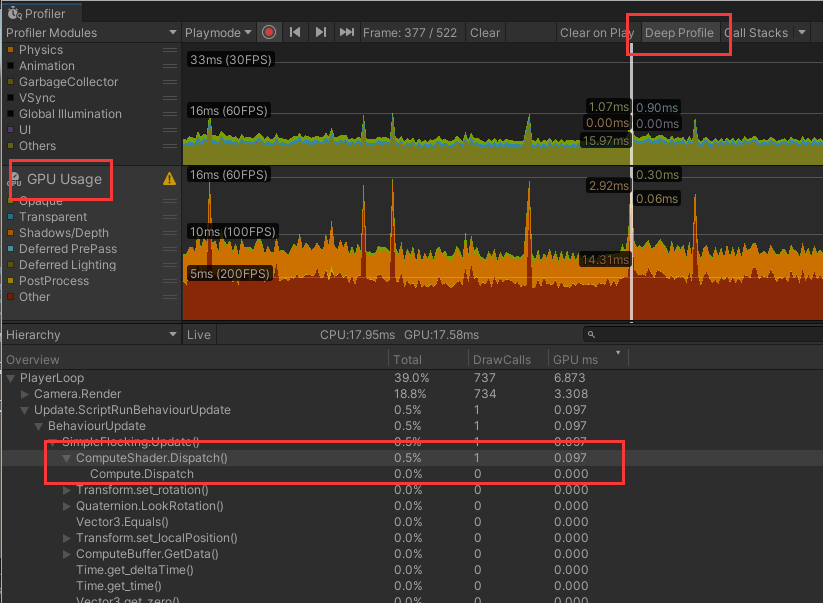
优化:DrawMeshInstanced
前面我们用 Instantiate 来初始化鸟群,其实我们也能通过 GPU instancing 来优化,用 Graphics.DrawMeshInstanced 来实例化 prefab。这个优化未包含在 Github 例子中,这里提供思路。
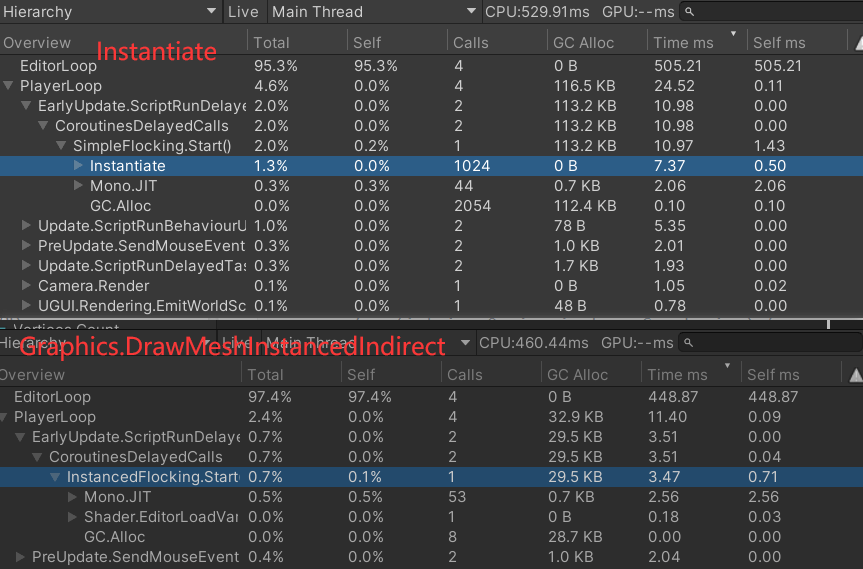
这么做的话,位置和旋转都要在传统 shader 中计算成变换矩阵应用在顶点上,因此为了防止 Compute Shader 数据传回 CPU 再传到 GPU 的传统 shader 的开销,需要两个 Shader 共享一个 StructuredBuffer 。
这样如果要给模型加动画的话,还得提前烘焙动画,将每一帧动画的顶点和当前帧数提前传到 vertex shader(or surface shader) 里做插值,这样做的话还能根据鸟的速度去控制动画的速率。
应用
- 遮挡剔除(Occlusion Culling)
- 环境光遮蔽(Ambient Occlusion)
- 程序化生成:
- terrain heightmap evaluation with noise, erosion, and voxel algorithms
- AI 寻路
- Compute Shader 做寻路有点不太好的就是往往游戏(CPU)需要知道计算结果,因此还要考虑 GPU 返回结果给 CPU 的延时。可以考虑做 CPU 端并行的方案,例如用 Job System。
- GPU 光线追踪
- 图像处理,例如模糊化等。
- 其他你想放到 GPU,但是传统着色器干不了的并行的解决方案。
原神
Unity线上技术大会-游戏专场|从手机走向主机 -《原神》主机版渲染技术分享

解压预烘焙的 Shadow Texture
在离线制作的时候,对于烘焙好的 shadow texture 做一个压缩,尽量地去保持精度,运行的时候解压的速度也非常快,用 Compute Shader 去解压的情况,1K×1K 的 shadow texture,解压只需要 0.05 毫秒。

做模糊处理
在进行模糊处理的时候,每个像素需要采取周边多个像素的数值进行混合,可以看到,如果使用传统的 PS,每个像素都会需要多次贴图采样,且这些采样结果实际上是可以在相邻其他像素的计算中进行重用的,因此为了进一步提升计算性能,《原神》这里的做法是将模糊处理放到 Compute Shader 中来完成。
具体的做法是,将相邻像素的采样结果存储在 局部存储空间(Local Data Share) 中,之后再模糊的时候取用,一次性完成四个像素的模糊计算,并将结果输出。[4]
天涯明月刀
《天涯明月刀》手游引擎技术负责人:如何应用GPU Driven优化渲染效果?| TGDC 2020

做遮挡剔除(Occlusion Culling)时,CPU 只能做到 Object Level,而 GPU 可以通过切分 Mesh 做进一步的剔除。

知乎上也有人尝试了实现:Unity实现GPUDriven地形。
斗罗大陆
三七研发,这款被称作 “目前最原汁原味的”《斗罗大陆》3D 手游都用到了哪些 Unity 技术?
利用 Compute Shader 对所有美术贴图逐像素对比,筛选出大量的重复、相似、屯余、大透明的贴图。
Clay Book
基于3D SDF 体渲染的黏土游戏:Claybook Game。
演讲:DD2018: Sebastian Aaltonen - GPU based clay simulation and ray tracing tech in Claybook
动图:https://gfycat.com/gaseousterriblechupacabra
Jelly in the sky
Finished my compute shader based game 这帖子的哥们写了六千多行 HLSL 代码做了一个完全在 GPU 执行的基于物理模拟的游戏。
Steam:Jelly in the sky on Steam
动图:https://gfycat.com/validsolidcanine
开源项目
- cinight/MinimalCompute
- krylov-na/Compute-shader-particles
- keijiro/Swarm
- ellioman/Indirect-Rendering-With-Compute-Shaders
缺点
虽然 Unity 帮我们做了跨平台的工作,但是我们仍然需要面对一些平台差异。
本小节内容大部分来自 Compute Shader : Optimize your game using compute。
- 难 Debug
- 数组越界,DX 上会返回 0,其它平台会出错。
- 变量名与关键字/内置库函数重名,DX 无影响,其他平台会出错。
- 如果 SBuffer 内结构的显存布局与内存布局不一致,DX 可能会转换,其他平台会出错。
- 未初始化的 SBuffer 或 Texture,在某些平台上会全部是 0,但是另外一些可能是任意值,甚至是NaN。
- Metal 不支持对纹理的原子操作,不支持对 SBuffer 调用
GetDimensions。 - ES 3.1 在一个 CS 里至少支持 4 个 SBuffer(所以,我们需要将相关联的数据定义为 struct)。
- ES 从 3.1 开始支持 CS,也就是说,在手机上的支持率并不是很高。部分号称支持 es 3.1+ 的 Android 手机只支持在片元着色器内访问 StructuredBuffer。
- 使用
SystemInfo.supportsComputeShaders来判断支不支持[5]
- 使用
最后
我相信 Compute Shader 这个词不少读者应该都会在其他地方见过,但是大都觉得这个技术离我们还很远。我身边的朋友问了问也没怎么了解过,更不要说在项目上用了,这也是这篇文章诞生的原因之一。
当我们面临使用 DOTS 还是 Compute Shader 的抉择时,更应该从项目本身出发,考虑计算应该放在 CPU 还是 GPU,Compute Shader 中跟 GPU 沟通的开销是否能够接受。读者也可以参考下 Unity Forum 中相关的讨论:Unity DOTS vs Compute Shader。
开始碎碎念,去年的年终总结也没写,今年到现在就憋出一篇文章,十分不应该。其实也是自己没什么好分享的,自己还需要多学习。当然也很高兴通过博客认识到不同朋友,这是我写作的动力,谢谢你们。
参考
- chenjd/Unity-Boids-Behavior-on-GPGPU
- 关于Compute Shader的一些基础知识记录
- Compute Shaders: Optimize your engine using compute / Lou Kramer, AMD
 wechat
wechat alipay
alipay





